翻译自: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/ 感谢作者, 尤其一些图
很漂亮,建议读者亲自读一遍英文.
内存管理是操作系统的核心; 是编程和系统管理的关键部分,在接下来的几篇文章中会从实际应用和内部角
度对内存管理模块进行分析. 内存管理的相关概念都是通用的,我们依照32位的linux和windowx86架构来分析. 这篇
文章主要介绍了进程的内存布局.
在多任务操作系统中每一个进程都有自己的内存空间,这个内存空间是虚拟内存空间,在32位机器中,每一
个进程有都4G的虚拟内存空间, 这些虚拟内存地址通过页表映射到真实的物理地址空间中, 这个映射关系是由内核
来管理的.每一个进程有自己的页表,但是一旦虚拟内存被启用,所有程序包括内核本身都会使用虚拟内存(在X86
CPU中大概只有一个CR3的寄存机存放的是物理地址,指向页表),所以虚拟地址空间的一部分需要划分给内核
使用: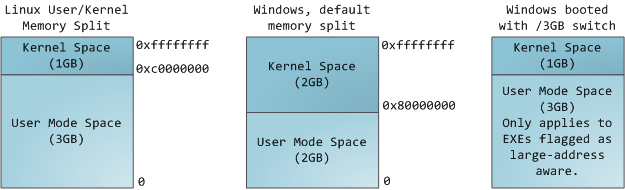
这并不意味着内核使用了很多物理内存, 内核只是预留了一段虚拟内存空间,当内核需要时可以映射为物理
内存, 内核的空间的页表有特殊flag(ring 2 or lower),当用户空间的代码访问内核页表时会触发page fault
在linux中, 内核空间在所有程序中指向的物理地址是一样的. 内核代码总是可寻址的.随时接受中断或系统调用. 与
此相反用户的地址空间则会随着进程的切换不断变化,
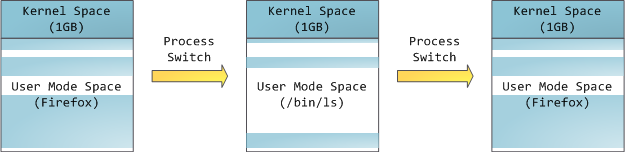
蓝色区域表示已映射物理内存的虚拟地址空间, 而白色表示还未映射. 在上面的例子中Firefox已经使用了大量
的虚拟地址空间. 不同的地址空间段对应程序不同的内存段包括堆、栈等等. 这些内存段落只是简单表示了一段空间而
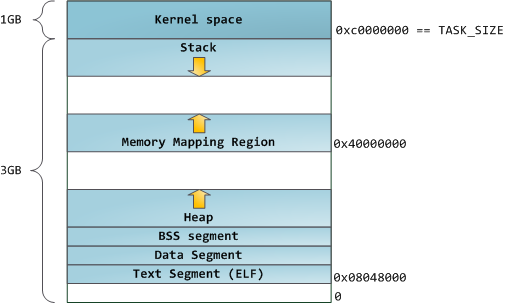
已,下图是一个标准的进程内存空间的布局:
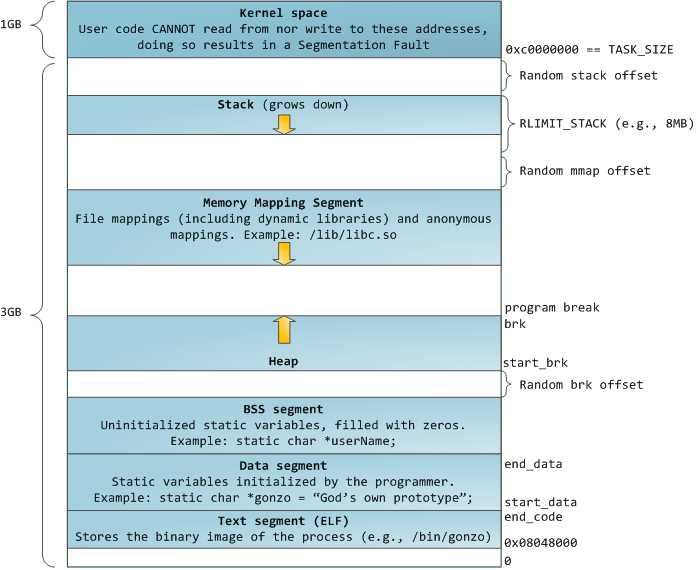
正常情况下每个进程的虚拟地址空间都基本上与上图类似. 这导致很容易远程利用安全漏洞攻击,这种攻击往往
需要知道进程的一个地址: 一个栈上的地址,或者一个lib库的一个函数的地址等等. 远程攻击者必须猜测
到这个地址然后进行攻击, 因为地址空间基本一样,早期的攻击比较容易,后来慢慢有了地址空间随机化技术,
linux会随机stack、mmap、heap在虚拟空间中的地址,一般通过在这些段空间起始地址加一个随机的offset.
但是32位的地址空间本来就很小,导致地址随机化的效果并不明显。
在进程的虚拟地址空间中靠近上面是栈,栈保存了本地变量、函数入参等.调用一个新的函数会在栈上创建
一个新的栈帧,每当函数返回值这个栈帧会被自动销毁,栈地址的管理非常简单可能是因为数据严格遵循LIFO的
顺序,不需要复杂的数据结构来跟踪栈地址,只需要一个栈顶指针可以搞定.而且栈的push和pop操作都非常快速
和简单. 另外栈空间一直重复使用(push\pop)有利于栈内存活跃在cpu cache中加快访问速度.对于线程来说每
一个线程都有自己的栈空间.
当栈空间用尽后继续push数据会触发栈空间的扩展. 这会触发一个 page fault 然后在内核中调用expand_stack()
函数. 该函数调用acct_stack_growth()来判断是否可以增长占空间. 如果当前栈空间的大小小于RLIMIT_STACK
(8M),可以继续增长栈空间. 该过程由内核完成进程不会感知到. 当用户的占空间已经达到允许的最大值时,内核会
给进程发送一个Segmentation Fault信号终止该进程. 进程的栈空间只会增大不会缩小,有点像联邦运算,只增不减.
栈空间的动态增长是唯一一种可以访问未映射的地址空间的情况. 其他任何访问未映射地址空间的操作都
会触发Segmentation Fault. 当然去写一个只读的地址空间也肯定会触发Segmentation Fault.
在栈空间下面是mmap区域, 在这些区域中内核将文件直接映射到地址空间中. 应用程序可以显示创建这些区域
通过调用mmap()/ CreateFileMapping()/MapViewOfFile(). 内存映射是一种高效和方便操作文件的一种方
式, 所以内存映射通常被用来加载动态链接库. 也可以创建一个匿名的mmap空间不指向任何文件而用来存储程序数据.
在linux中如果用户malloc 一个非常大块的内存,标准c库会通过mmap来创建这块内存区间而不使用Heap内存,这里的
大块是指超过MMAP_THRESHOLD( 128k), MMAP_THRESHOLD可以通过mallopt()函数动态调整.
说到堆内存,它一个我们下面要讲述的重要的一个地址空间,堆提供了程序运行时的内存分配, 堆内存的生
命周期在函数之外. 大部分语言都提供了堆内存管理函数, 如C语言的malloc() free().
如果当前堆的内存足够程序使用,不许要与内核交互,在当前堆中寻找可用内存就行, 否则的话需要调用brk()
系统调用在内核中增大堆内存. 堆内存分贝的算法非常复杂, 既要保证内存分配的实时性和快速,又要尽量避免堆中
出现过多碎片, 如下图所示:

最后,我看来看一下最先面的BSS、data和代码段, 在C语言中BSS和data存放了静态(全局)变量, 其中BSS
存放了未初始化的变量(static int cntActiveUsers),BSS段是匿名的不映射任何文件. data段存放了代码中已
初始化的静态变量, data段不是匿名的而是映射了程序二进制文件中存已初始化静态变量的部分. 例如 static int
cntWorkerBees = 10 会存放在data段, 虽说data段映射文件的一部分,这是私有映射数据在内存中的改变不会
影响到文件.
下图的data段 包含一个4-byte的内存指针, 这个指针在data段, 但是这个指针指向的字符串却在text段,
text段存放了一些子只读的字符串信息, text段也是你二进制文件在内存中的映射,同样向text段写操作会导致
SegmetationFault. 这样可以避免一些指针错误. 当然这些指针错误最好在编码时就能发现.
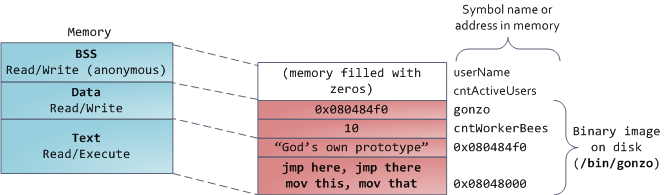
在linux中可以通过 查看/proc/进程ID/maps文件内容来获得进程的内存布局信息,一个内存段可能包含
多个子区域例如 通过mmap的内存通常有自己的区域, 但是程序加载的so还包括自己的类似BSS和data部分. 下
一篇文章会详细介绍一下内存管理中的区域概念.你可以通过nm和objdump命令来查看某一个可执行文件的符号,
地址,段等信息, 上文所描述的就是linux所谓的”灵活”的虚拟内存布局, 这样的默认布局已经好多年了, 它假设
我们有一个RLITMIT_STACK变量,如果没有的话, linux的经典内存布局如下:
转载请注明出处,谢谢。。